在K8S中一个网络请求是如何到达应用的
# 一、介绍
网络是Kubernetes中比较复杂的一部分,本文希望通过一种实战的角度从宏观到微观的向读者展示一个网络请求是如何到达应用内部的。这里面又分为以下两种情况:
- 集群外部的一个请求如何到达应用?
- 集群内部的一个请求如何到达应用?
# 二、典型应用的网络请求链路
# 2.1 集群外部流量如何到达一个应用
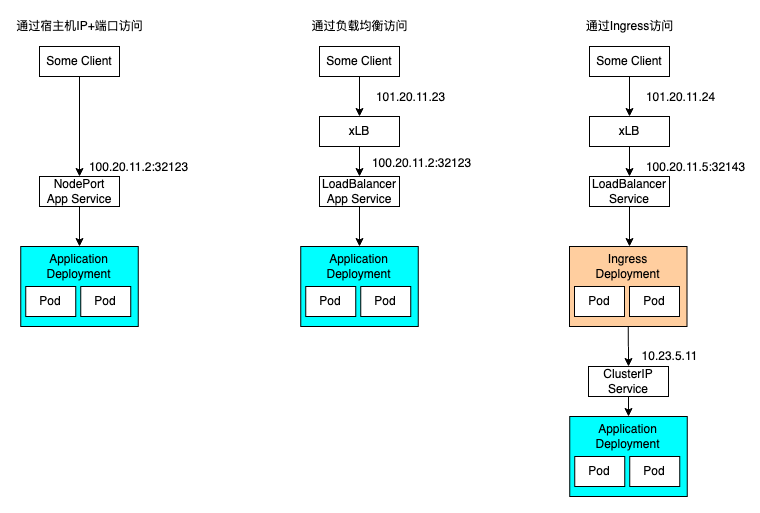 2.1.1 通过NodePort类型的Service访问
从根源上讲,这种方式是唯一的集群外部访问方式。
2.1.1 通过NodePort类型的Service访问
从根源上讲,这种方式是唯一的集群外部访问方式。
kubectl create deployment --image saltbo/hello-world hwa
kubectl expose deployment hwa --type NodePort --port 8000 --name hwa-np
2.1.2 通过LoadBalancer类型的Service访问
这种方式本质上还是使用的NodePort,只不过这种类型的Service是配合云厂商的cloud-controller-manager将NodePort挂载到云厂商的LB上面。
kubectl expose deployment hwa --type LoadBalancer --port 8000 --name hwa-lb
2.1.3 通过Ingress访问 这种方式实际上是通过一个反向代理转发了请求。而Ingress本身还是通过LB进行访问。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: hwa-ingress
spec:
ingressClassName: nginx
rules:
- host: "hwa.example.com"
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: hwa
port:
number: 8000
2.1.4 是否还有别的方式进行访问
- hostNetwork
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
hostNetwork: true
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 8000
- hostPort
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
hostPort: 8000
# 2.2 集群内部流量如何到达一个应用
2.2.1 通过Service访问
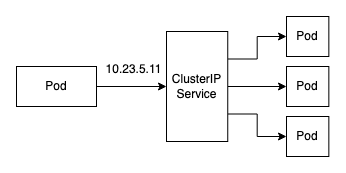 在 Kubernetes 集群中,每个 Node 运行一个
在 Kubernetes 集群中,每个 Node 运行一个 kube-proxy 进程。 kube-proxy 负责为 Service 实现了一种 VIP(虚拟 IP)的形式。

ip ad | grep ipvs
查看基于ipvs的ClusterIP到PodIP的转发规则
ipvsadm -Ln
2.2.2 通过服务发现直接进行Pod间访问 回顾下docker的网络的网络模式
| bridge模式 | (默认为该模式)此模式会为每一个容器分配、设置IP等,并将容器连接到一个docker0虚拟网桥,通过docker0网桥以及Iptables nat表配置与宿主机通信。 |
|---|---|
| host模式 | 容器和宿主机共享Network namespace。 |
| container模式 | 容器和另外一个容器共享Network namespace。 kubernetes中的pod就是多个容器共享一个Network namespace。 |
| none模式 | 该模式关闭了容器的网络功能。 |
- 相同网段的ip可以互相访问
- 不同网段的ip如果想要互相访问,需要配置路由表
::: tip 👉
同一个节点上Pod间通信
:::
CNI,它的全称是 Container Network Interface,即容器网络的 API 接口。kubernetes 网络的发展方向是希望通过插件的方式来集成不同的网络方案, CNI 就是这一努力的结果。CNI 只专注解决容器网络连接和容器销毁时的资源释放,提供一套框架,所以 CNI 可以支持大量不同的网络模式,并且容易实现。平时比较常用的 CNI 实现有 Flannel、Calico、Weave 等。CNI定义如下:
type CNI interface {
AddNetworkList(ctx context.Context, net *NetworkConfigList, rt *RuntimeConf) (types.Result, error)
CheckNetworkList(ctx context.Context, net *NetworkConfigList, rt *RuntimeConf) error
DelNetworkList(ctx context.Context, net *NetworkConfigList, rt *RuntimeConf) error
GetNetworkListCachedResult(net *NetworkConfigList, rt *RuntimeConf) (types.Result, error)
GetNetworkListCachedConfig(net *NetworkConfigList, rt *RuntimeConf) ([]byte, *RuntimeConf, error)
AddNetwork(ctx context.Context, net *NetworkConfig, rt *RuntimeConf) (types.Result, error)
CheckNetwork(ctx context.Context, net *NetworkConfig, rt *RuntimeConf) error
DelNetwork(ctx context.Context, net *NetworkConfig, rt *RuntimeConf) error
GetNetworkCachedResult(net *NetworkConfig, rt *RuntimeConf) (types.Result, error)
GetNetworkCachedConfig(net *NetworkConfig, rt *RuntimeConf) ([]byte, *RuntimeConf, error)
ValidateNetworkList(ctx context.Context, net *NetworkConfigList) ([]string, error)
ValidateNetwork(ctx context.Context, net *NetworkConfig) ([]string, error)
}
源码:cni/api.go at main · containernetworking/cni (opens new window)
::: tip 💡
Flannel Vxlan示意图
:::
- 给Pod分配IP
- 给每个Node创建一个子网
- 维护所有子网的路由 数据传递过程
- 源容器向目标容器发送数据,数据首先发送给docker0网桥
- docker0网桥接受到数据后,将其转交给flannel.1虚拟网卡处理
- flannel.1接受到数据后,对数据进行封装,并发给宿主机的eth0
- 对在flannel路由节点封装后的数据,进行再封装后,转发给目标容器Node的eth0
- 目标容器宿主机的eth0接收到数据后,对数据包进行拆封,并转发给flannel.1虚拟网卡;
- flannel.1 虚拟网卡接受到数据,将数据发送给docker0网桥;
- 最后,数据到达目标容器,完成容器之间的数据通信。
# 三、总结归纳
# 3.1 Kubernetes中向外暴露服务的方式
- 通过NodePort类型的Service
- 通过LoadBalancer的Service
- 通过Ingress
- 通过HostPort或HostNetwork
# 3.2 Service背后的kube-proxy的模式
- userspace:用户态代理,性能差
- iptables:内核态代理,无需在用户空间和内核空间之间切换,处理流量具有较低的系统开销
- ipvs:类似iptables,但性能更好
# 3.3 CNI的一种实现,Flannel中的模式
- udp:使用用户态udp封装,默认使用8285端口。由于是在用户态封装和解包,性能上有较大的损失
- vxlan:vxlan封装,需要配置VNI,Port(默认8472)和GBP (opens new window)
- host-gw:直接路由的方式,将容器网络的路由信息直接更新到主机的路由表中,仅适用于二层直接可达的网络
- aws-vpc:使用 Amazon VPC route table 创建路由,适用于AWS上运行的容器
- gce:使用Google Compute Engine Network创建路由,所有instance需要开启IP forwarding,适用于GCE上运行的容器
- ali-vpc:使用阿里云VPC route table 创建路由,适用于阿里云上运行的容器
# 四、参考文档
- 原文出处:
- 原文作者: https://github.com/saltbo
- 原文链接:
- 版权声明:本文欢迎任何形式转载,转载时完整保留本声明信息(包含原文链接、原文出处、原文作者、版权声明)即可。本文后续所有修改都会第一时间在原始地址更新。